Distributed Systems
A distributed system is a group of components working together to achieve a unified goal. In terms of systems, component is nothing but a process.
Why do we need Distributed Systems ?
One single answer to this question - Scalability. Lets a take a simple example of web server. A web server receives requests from client, processes the request and sends back the response.

One typical server handles 10000 active concurrent connections, even if we consider ports space is 0-65k (ignoring memory requirements for that many active connections), we are limited by the 65000 for total number of requests served by a single server. So we need more than one server if we have requests greater than 65k. To solve this problem we have multiple servers doing the same job of serving the client requests. The moment we introduced mutiple servers , we need to handle the problem of sharing the state of webserver across multiple web servers. If we do not have any dynamic state, ie serving static content like images, text , we can simply replicate data on both the servers and each server uses its own data and process client requests.
Considered the scenario in which we need to share the state across mutiple servers. Now we have 2 solutions.
Method 1:
One server stores the entire state or data. Another server requests whenever data is required. But this approach has couple of flaws. One of the flaw is availability of service. If server 1 goes down, server 2 cannot serve requests, since server 2 do not have access to data. So even after scaling to 2 machines we could only guarantee availbility of 1 machine.
Method 2:
We host data in another machine ie. database. So even though server-0 goes down, server-1 could still server requests accessing data from database.
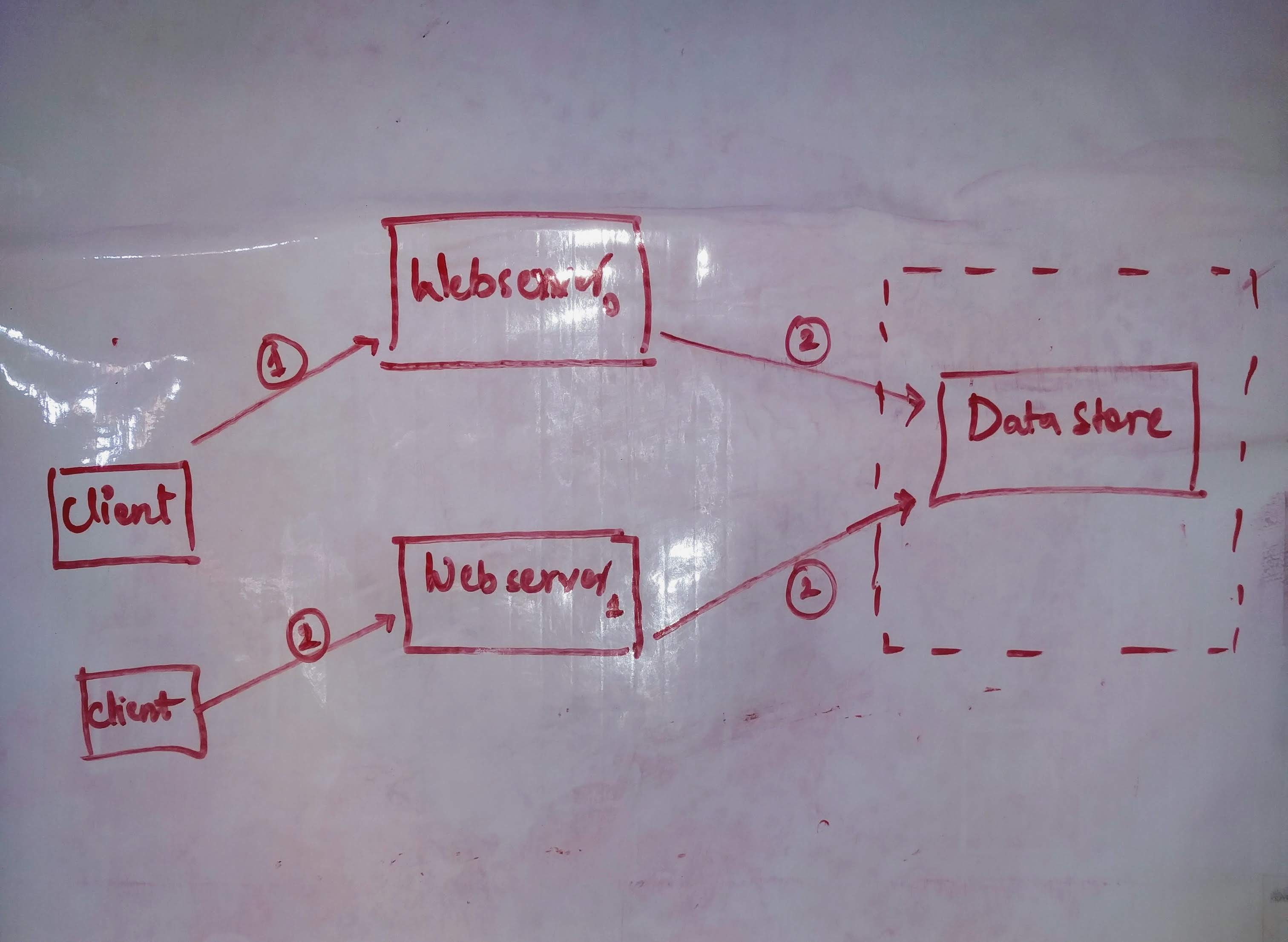
Lets come back to original question . Did we scale beyond maximum capacity of one server ? No, earlier webserver has the bottleneck of maximum connections, now the database has the problem of maximum connection. But this solution is better than previous solution if the server is a bit smart. If the server makes a new connection for every request it receives then we have no additional advantage. Now that server has bunch of requests it could make batch of requests in one single connection instead of requesting multiple connections.
Now what if 1 database server has to serve requests more than its capacity. Like we did earlier, we could launch another instance of database machine. But we have another problem here, since data or state needs to be same on both database servers, we need to synchronize. So we need to design systems which are in sync and handle requests.